

自 iPhone 問世以來,攝影功能一直是 Apple 專注的核心。幾年下來,他們釋出了許多驚艷的功能,讓大家無法捨離 iPhone。因為 Apple 不斷增加圖像智能功能,讓使用者能夠拍出更好的相片。
具體來說,Apple 在電腦視覺領域大量投資,其 2017 年釋出的 Vision 框架,也會每年推出重大更新。
Apple 推出了臉部偵測 (face detection)、物件追蹤 (object tracking)、捕捉品質 (capture quality)、及圖像相似度 (image similarity) 功能,讓開發者能夠整合複雜的電腦視覺演算法,來建置基於照片的 AI App。
在 WWDC 2019 新釋出的功能中,Vision 的文字辦認 (text recognition) 和視覺顯著 (Saliency) 功能備受關注。
不過,這不是我們這篇文章的重點。
我們的目標
- 本篇文章的目標,是深入探究 Vision 的矩形偵測 (rectangle detection) 請求。
- 我們將利用
VNDetectRectanglesRequest探索各種可能的設定。 - 在本文中,我們將開發一個 App,用於掃描信用卡或其他尺寸相似的名片,並且對 App 的即時相機畫面進行剪裁。
- 最後,我們將使用 Vision 的文字辨認請求,只解析卡片裡我們需要的數值。這些數值由使用者透過手勢來選擇。
矩形偵測的需求
如果你試用過 iOS 13 的 Document Camera 來掃描文件(它內建於 Notes 和 Files App 內),你會注意到它會要求你手動設置文件的邊角位置。
不過利用 Vision 的矩形偵測,我們可以自動偵測出文件(通常為矩形)的邊角。
VNDetectRectanglesRequest
Vision 的矩形偵測請求是一個基於圖像的請求,用於在圖像中尋找矩形區域。而除了指定信心度門檻 (confidence threshold) 外,我們還可以用以下的屬性來客製這個請求:
- VNAspectRatio:這個屬性讓我們指定 Vision 請求的最小及最大比例,以限制想要偵測的矩形類型。
比如說,如果我們設定minimumAspectRatio及maximumAspectRatio為 1,就可以只偵測正方形。 - Minimum Size:這個屬性讓我們指定希望偵測到的矩形的最小尺寸。它需要是 0 到 1.0 之間的數字,而預設值為 0.2。
- Maximum Observations:這是一個整數屬性,用於指定 Vision 最多可以回傳多少個矩形。
- 兩邊之間的角度:我們可以利用
quadratureTolerance屬性,來指定矩形的角度比 90 度大於或小於多少。
在接下來的段落中,我們將建立一個 iOS App,利用 Vision 框架搭配 AVFoundation,來用客製的相機掃描文件。
在剪裁偵測區域並儲存為圖像前,我們將進行透視校正 (Perspective Correction)。讓我們開始吧!
開始
首先,開啟 Xcode 並建立一個 Single View Application。記得在 info.plist 檔案裡加入 NSCameraUsageDescription 鍵,來新增相機權限的描述。
設定相機輸入
在下面的程式碼中,我們設定了後置相機,並將媒體類型 (Media Type) 設定為 Video,然後將它加進 AVCaptureSession:
private let captureSession = AVCaptureSession()
private func setCameraInput() {
guard let device = AVCaptureDevice.DiscoverySession(
deviceTypes: [.builtInWideAngleCamera, .builtInDualCamera, .builtInTrueDepthCamera],mediaType: .video, position: .back).devices.first else {
fatalError("No back camera device found.")
}
let cameraInput = try! AVCaptureDeviceInput(device: device)
self.captureSession.addInput(cameraInput)
}接下來,我們需要將相機畫面加入到 ViewController 的視圖裡。
顯示相機畫面以及設定輸出
在以下的程式碼中,我們顯示了即時相機畫面,並設定了輸出的函式。最後,我們把輸出的視頻影格 (video frame) 丟給 Vision 請求:
private lazy var previewLayer = AVCaptureVideoPreviewLayer(session: self.captureSession)
private let videoDataOutput = AVCaptureVideoDataOutput()
private func showCameraFeed() {
self.previewLayer.videoGravity = .resizeAspectFill
self.view.layer.addSublayer(self.previewLayer)
self.previewLayer.frame = self.view.frame
}
private func setCameraOutput() {
self.videoDataOutput.videoSettings = [(kCVPixelBufferPixelFormatTypeKey as NSString) : NSNumber(value: kCVPixelFormatType_32BGRA)] as [String : Any]
self.videoDataOutput.alwaysDiscardsLateVideoFrames = true
self.videoDataOutput.setSampleBufferDelegate(self, queue: DispatchQueue(label: "camera_frame_processing_queue"))
self.captureSession.addOutput(self.videoDataOutput)
guard let connection = self.videoDataOutput.connection(with: AVMediaType.video),
connection.isVideoOrientationSupported else { return }
connection.videoOrientation = .portrait
}為了接收相機的影格,我們需要遵從 AVCaptureVideoDataOutputSampleBufferDelegate 協定,並實作 captureOutput 函式。
現在相機已經準備好了!讓我們加入三個函式到 ViewController 裡的 viewDidLoad 方法,然後簡單呼叫 AVCaptureSession 實例上的 startRunning 函式。
override func viewDidLoad() {
super.viewDidLoad()
self.setCameraInput()
self.showCameraFeed()
self.setCameraOutput()
self.captureSession.startRunning()
}設定 Vision 請求
現在是時候設定 Vision 矩形偵測請求了。在以下的函式 detectRectangles 裡,我們設定了 VNDetectRectanglesRequest,並將它傳送給圖像請求處理器來開始流程:
private func detectRectangle(in image: CVPixelBuffer) {
let request = VNDetectRectanglesRequest(completionHandler: { (request: VNRequest, error: Error?) in
DispatchQueue.main.async {
guard let results = request.results as? [VNRectangleObservation] else { return }
self.removeMask()
guard let rect = results.first else{return}
self.drawBoundingBox(rect: rect)
if self.isTapped{
self.isTapped = false
self.doPerspectiveCorrection(rect, from: image)
}
}
})
request.minimumAspectRatio = VNAspectRatio(1.3)
request.maximumAspectRatio = VNAspectRatio(1.6)
request.minimumSize = Float(0.5)
request.maximumObservations = 1
let imageRequestHandler = VNImageRequestHandler(cvPixelBuffer: image, options: [:])
try? imageRequestHandler.perform([request])
}在上面的程式碼中,有幾個地方需要注意:
- 我們把
minimumAspectRatio設定為 1.3,而maximumAspectRatios則設定為 1.7,因為大多數的信用卡及名片都在這個比例範圍內。 - 上述的函式會被以下函式所呼叫:
func captureOutput(
_ output: AVCaptureOutput,
didOutput sampleBuffer: CMSampleBuffer,
from connection: AVCaptureConnection) {
guard let frame = CMSampleBufferGetImageBuffer(sampleBuffer) else {
debugPrint("unable to get image from sample buffer")
return
}
self.detectRectangle(in: frame)
}- 在完成處理器 (Completion Handler) 裡,Vision 請求的回傳結果是
VNRectangleObservation型別,它是由boundingBox和confidence數值組成。 - 我們利用
boundingBox屬性,繪製一個圖層到偵測矩型的相機上面。 doPerspectiveCorrection函式是用來修復扭曲的圖像的,我們將會在稍後的部分進一步了解這一點。當使用者點擊 “Scan” 按鈕,來從相機畫面提取完整的裁切卡片時,就會呼叫這個函式。
在相機視圖上繪製邊界框 (Bounding Box)
Vision 的邊界框座標屬於標準座標系統,它的原點位於螢幕視窗的左下角。
因此,我們需要將 Vision 邊界框 CGRect 轉換為圖像座標系統(原點在左上角),如下面的程式碼所示:
func drawBoundingBox(rect : VNRectangleObservation) {
let transform = CGAffineTransform(scaleX: 1, y: -1).translatedBy(x: 0, y: -self.previewLayer.frame.height)
let scale = CGAffineTransform.identity.scaledBy(x: self.previewLayer.frame.width, y: self.previewLayer.frame.height)
let bounds = rect.boundingBox.applying(scale).applying(transform)
createLayer(in: bounds)
}
private func createLayer(in rect: CGRect) {
maskLayer = CAShapeLayer()
maskLayer.frame = rect
maskLayer.cornerRadius = 10
maskLayer.opacity = 0.75
maskLayer.borderColor = UIColor.red.cgColor
maskLayer.borderWidth = 5.0
previewLayer.insertSublayer(maskLayer, at: 1)
}我們不使用 CGAffineTransform 來將邊界框轉換為圖像的座標空間,而是使用 Vision 框架的內建方法:
func VNNormalizedRectForImageRect(_ imageRect: CGRect,
_ imageWidth: Int,
_ imageHeight: Int) -> CGRect當 maskLayer 被設定在相機畫面偵測到的矩形上時,你會看到這樣的畫面:

我們已經完成一半了!在下個階段,我們要在邊界框裡提取圖像。讓我們來看看怎樣做吧。
從邊界框提取圖像
doPerspectiveCorrection 函式從緩衝區 (Buffer) 中取得 Core Image,並將它的邊角從標準座標空間轉換為圖像座標空間,然後套用透視校正濾鏡來給我們圖像。程式碼如下列所示:
func doPerspectiveCorrection(_ observation: VNRectangleObservation, from buffer: CVImageBuffer) {
var ciImage = CIImage(cvImageBuffer: buffer)
let topLeft = observation.topLeft.scaled(to: ciImage.extent.size)
let topRight = observation.topRight.scaled(to: ciImage.extent.size)
let bottomLeft = observation.bottomLeft.scaled(to: ciImage.extent.size)
let bottomRight = observation.bottomRight.scaled(to: ciImage.extent.size)
ciImage = ciImage.applyingFilter("CIPerspectiveCorrection", parameters: [
"inputTopLeft": CIVector(cgPoint: topLeft),
"inputTopRight": CIVector(cgPoint: topRight),
"inputBottomLeft": CIVector(cgPoint: bottomLeft),
"inputBottomRight": CIVector(cgPoint: bottomRight),
])
let context = CIContext()
let cgImage = context.createCGImage(ciImage, from: ciImage.extent)
let output = UIImage(cgImage: cgImage!)
UIImageWriteToSavedPhotosAlbum(output, nil, nil, nil)
}UIImageWriteToSavedPhotosAlbum 函式是用來儲存圖像到裝置裡的相簿的。
如果你直接傳送 CIImage 到 UIImage 初始器的話,圖像就不會在相簿裡顯示。因此,最關鍵的是你要先要將 CIImage 轉換為 CGImage,然後再將它傳送給 UIImage。
讓我們來看看套用了透視校正的圖像:

從上面例子中,我們看到在 Core Image 上套用透視校正濾鏡,就可以固定圖像的方向。
接著,讓我們看一下從掃描圖像中提取特定文字的功能吧!
更完善的 Vision 文字辨識功能
iOS 13 的 Vision 在 VNRecognizeTextRequest 添加了文字識別功能,它之前只能告訴我們是否有文字,我們須使用 Core ML 模型來解析該值表示的文字。
具體來說,我們以前需要使用正規表示式 (Regular expression),這不僅沒有效率,而且也無法廣泛運用。如果使用正規表示式,要過濾不同類型的信用卡,就需要支援很多的個別例子。例如,不是所有的信用卡都有 16 位數字,像 AMEX 信用卡就只有 15 碼。
相反,我們會讓使用者利用手勢在圖像上建立一個可移動的矩形。接著,我們會解析使用者所選區塊裡的文字。這不僅讓過程更有效率,而且也讓使用者控制所共享的資料。
為了建立一個可移動的矩形,我們將追蹤使用者在掃描圖像上的點擊,並重繪選擇的區域,如下所示:
let overlay = UIView()
var lastPoint = CGPoint.zero
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
clearOverlay()
if let touch = touches.first {
lastPoint = touch.location(in: self.view)
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
if let touch = touches.first {
let currentPoint = touch.location(in: view)
drawSelectionArea(fromPoint: lastPoint, toPoint: currentPoint)
}
}
func drawSelectionArea(fromPoint: CGPoint, toPoint: CGPoint) {
let rect = CGRect(x: min(fromPoint.x, toPoint.x), y: min(fromPoint.y, toPoint.y), width: abs(fromPoint.x - toPoint.x), height: abs(fromPoint.y - toPoint.y))
overlay.frame = rect
}
func clearOverlay(){
overlay.isHidden = false
overlay.frame = CGRect.zero
}使用者選擇了一個矩形區域,並按下 “Extract” 按鈕後,我們利用矩形區域裁剪圖像,並送到 Vision Request。
我沒有放上 TextExtractorVC.swift 的完整程式碼,以下只放上相關的程式碼片段:
@objc func doExtraction(sender: UIButton!){
processImage(snapshot(in: imageView, rect: overlay.frame))
}
private func processImage(_ image: UIImage) {
recognizeTextInImage(image)
}
func snapshot(in imageView: UIImageView, rect: CGRect) -> UIImage {
return UIGraphicsImageRenderer(bounds: rect).image { _ in
clearOverlay()
imageView.drawHierarchy(in: imageView.bounds, afterScreenUpdates: true)
}
}
private func setupVision() {
textRecognitionRequest = VNRecognizeTextRequest { (request, error) in
guard let observations = request.results as? [VNRecognizedTextObservation] else { return }
var detectedText = ""
for observation in observations {
guard let topCandidate = observation.topCandidates(1).first else { return }
detectedText += topCandidate.string
detectedText += "\n"
}
DispatchQueue.main.async{
self.digitsLabel.text = detectedText
}
}
textRecognitionRequest.recognitionLevel = .accurate
}
private func recognizeTextInImage(_ image: UIImage) {
guard let cgImage = image.cgImage else { return }
textRecognitionWorkQueue.async {
let requestHandler = VNImageRequestHandler(cgImage: cgImage, options: [:])
do {
try requestHandler.perform([self.textRecognitionRequest])
} catch {
print(error)
}
}
}以下是最後 App 的成果:

上面的動畫沒有擷取我的信用卡號碼,而只是擷取了信用卡正面的資訊。
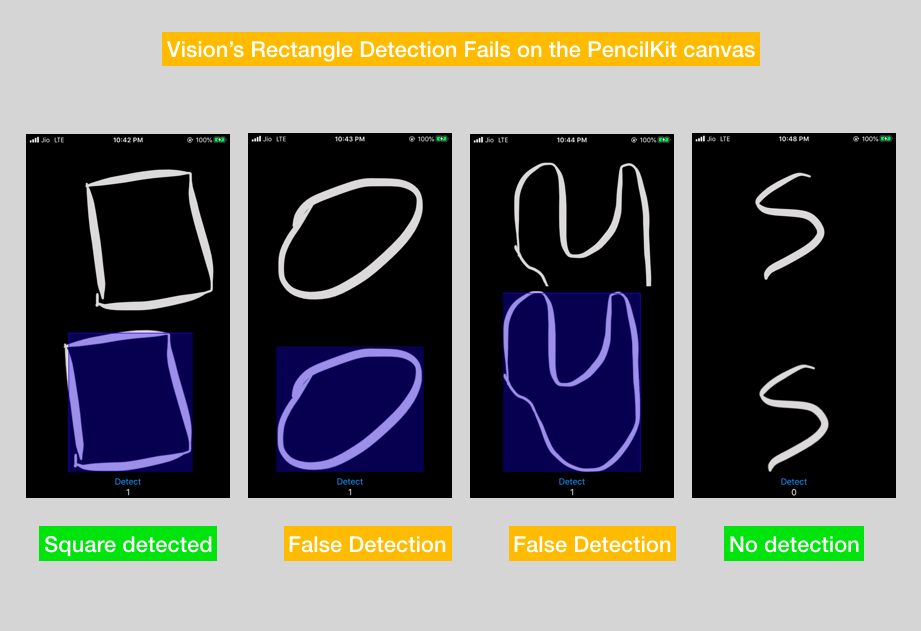
當使用 PencilKit 時,準確性不那麼好
Vision 的矩形偵測在手繪的形狀上運作得不太好。以下是我使用上述 Vision 請求時,對 PencilKit 框架進行的實驗:
總結
在本篇文章中,我們製作了電腦視覺的一個經典 App。其中,我們在即時相機畫面裡用了矩形偵測請求,來偵測信用卡並擷取出來,同時考慮其方向及變形的情況。
然後,我們在掃描的圖像上實作了文字辨認功能,來取得信用卡上的文字。我們讓使用者選擇想要解析的區域,這樣除了讓他們可以控制自己的資訊外,也可以避免擷取到不必要的資訊。
要在卡片上取得想要的資訊,你也可以在要辨認的文字上設定邊界框,並且在上面做點擊測試 (hit test)!
你可以在 GitHub 程式庫中取得完整的程式碼。
本篇文章到此為止,謝謝你的閱讀。


