

Vision 框架長期以來一直包含文字識別功能。我們已經有詳細的教程,向你展示如何使用 Vision 框架掃描圖像並執行文字識別。之前,我們使用了 VNImageRequestHandler 和 VNRecognizeTextRequest 來從圖像中提取文字。
多年來,Vision 框架已經顯著演變。在 iOS 18 中,Vision 引入了利用 Swift 6 新功能的 API。在本教程中,我們將探索如何使用這些新 API 來執行文字辨識。你會驚訝於框架的改進,它節省了大量程式碼來實現相同的功能。
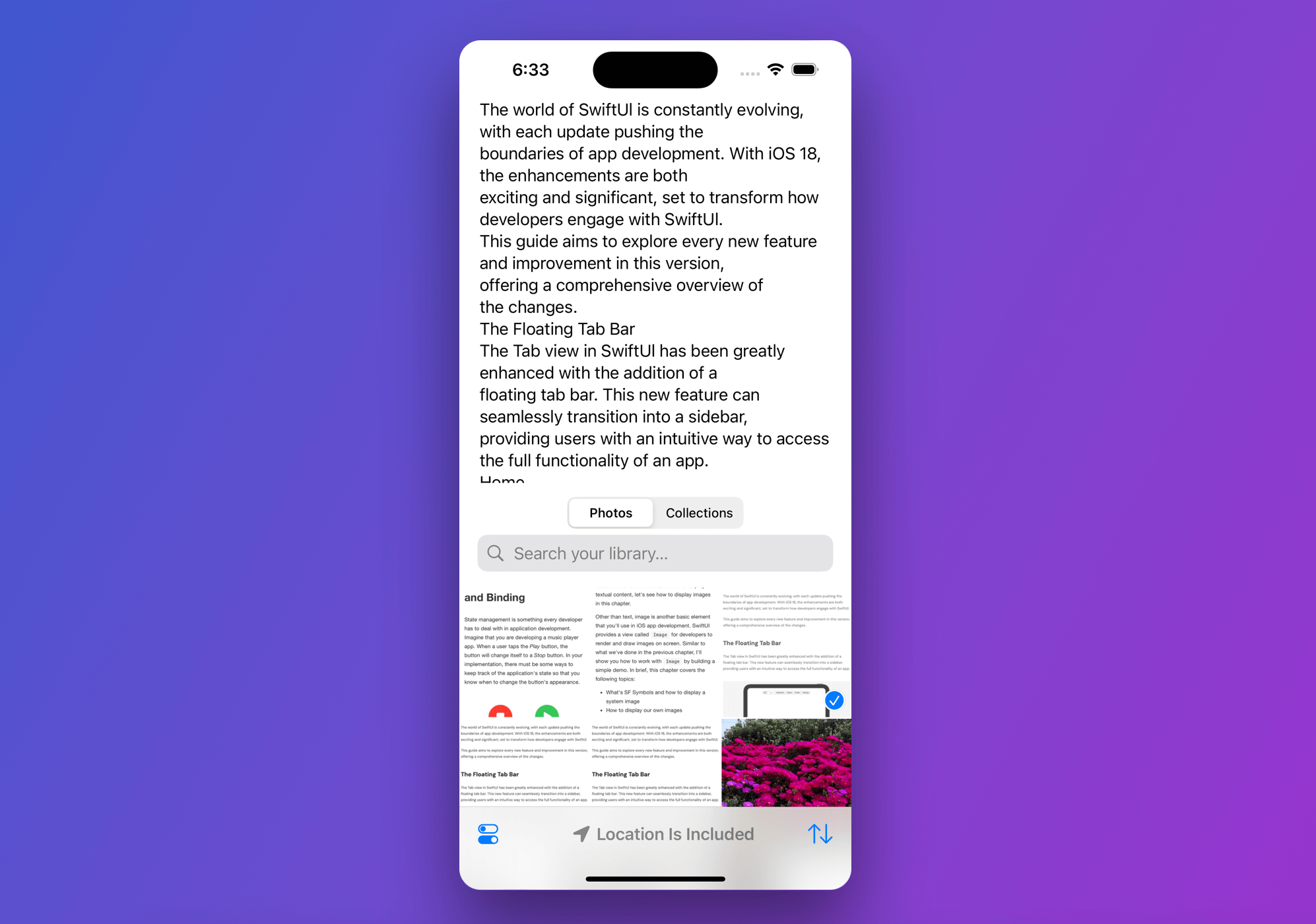
一如既往,我們將創建一個示範 App 來引導你使用這些 API。我們將構建一個簡單的 App,允許用戶從照片庫中選擇圖像,應用程序將即時提取其中的文字。
讓我們開始吧。
使用 PhotosPicker 加載照片庫
假設你已經在 Xcode 16 上創建了一個新的 SwiftUI 項目,轉到 ContentView.swift 並開始構建演示應用程序的基本 UI:
import SwiftUI
import PhotosUI
struct ContentView: View {
@State private var selectedItem: PhotosPickerItem?
@State private var recognizedText: String = "No text is detected"
var body: some View {
VStack {
ScrollView {
VStack {
Text(recognizedText)
}
}
.contentMargins(.horizontal, 20.0, for: .scrollContent)
Spacer()
PhotosPicker(selection: $selectedItem, matching: .images) {
Label("Select a photo", systemImage: "photo")
}
.photosPickerStyle(.inline)
.photosPickerDisabledCapabilities([.selectionActions])
.frame(height: 400)
}
.ignoresSafeArea(edges: .bottom)
}
}
我們使用 PhotosPicker 訪問照片庫並在屏幕的下部加載圖像。螢幕的上部設有一個滾動視圖來顯示識別出的文字。
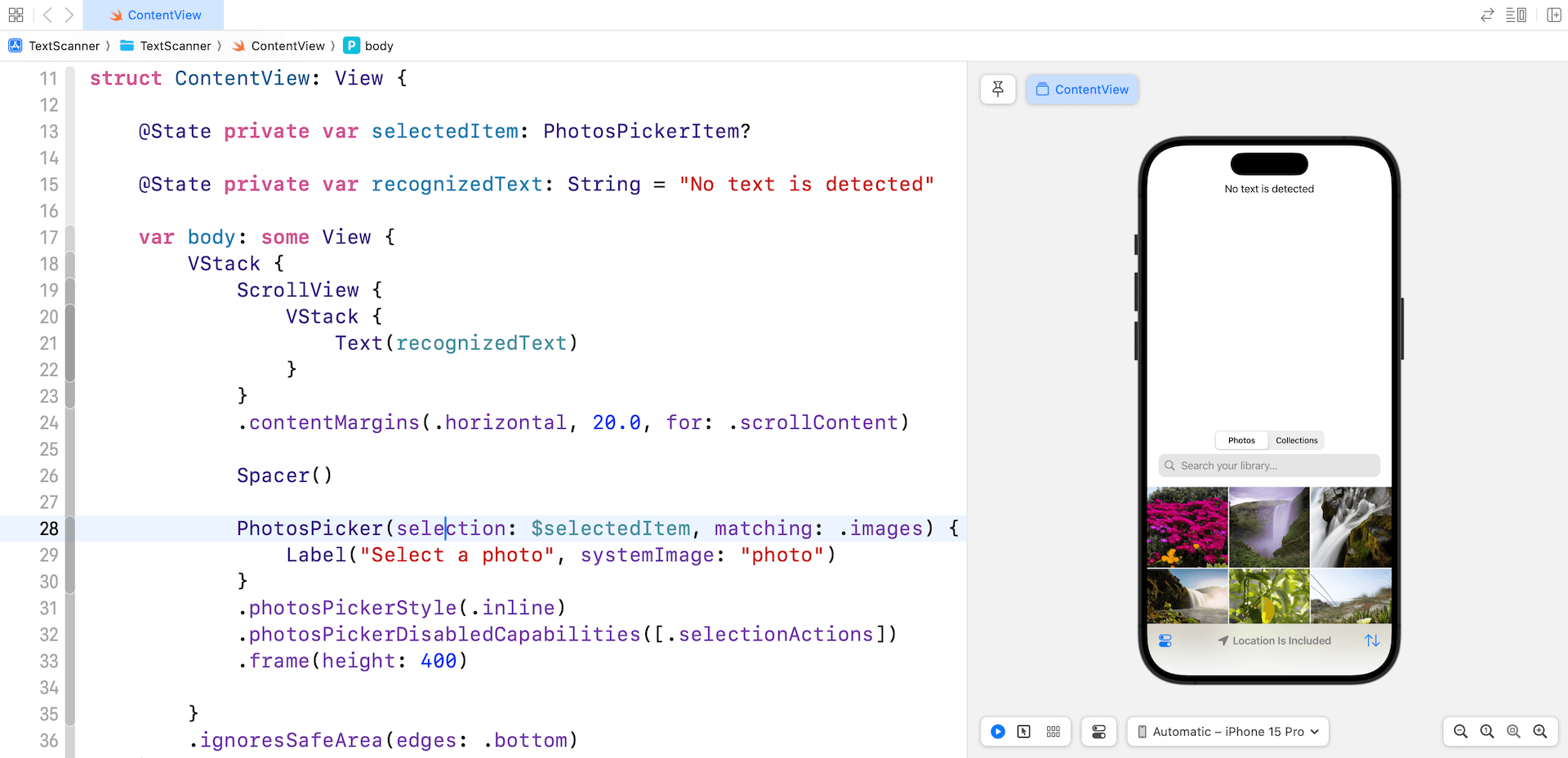
我們有一個狀態變數來追踪所選照片。為了檢測選定的圖像並將其加載為數據,你可以將 onChange 修飾符附加到 PhotosPicker 視圖,如下所示:
.onChange(of: selectedItem) { oldItem, newItem in
Task {
guard let imageData = try? await newItem?.loadTransferable(type: Data.self) else {
return
}
}
}
使用 Vision 進行文字識別
Vision 框架中的新 API 簡化了文字識別的實現。Vision 提供了 31 種不同的請求類型,每種類型都針對特定的圖像分析。例如,DetectBarcodesRequest 用於識別和解碼條形碼。對於我們的目的,我們將使用 RecognizeTextRequest。
在 ContentView 中,添加一個 import 語句來導入 Vision,並創建一個名為 recognizeText 的新函數:
private func recognizeText(image: UIImage) async {
guard let cgImage = image.cgImage else { return }
let textRequest = RecognizeTextRequest()
let handler = ImageRequestHandler(cgImage)
do {
let result = try await handler.perform(textRequest)
let recognizedStrings = result.compactMap { observation in
observation.topCandidates(1).first?.string
}
recognizedText = recognizedStrings.joined(separator: "\n")
} catch {
recognizedText = "Failed to recognized text"
print(error)
}
}
這個函數接收一個 UIImage 對象,即所選的照片,並從中提取文字。RecognizeTextRequest 對象旨在識別圖像中的矩形文字區域。
ImageRequestHandler 對象處理給定圖像上的文字識別請求。當我們調用其 perform 函數時,它會將結果以 RecognizedTextObservation 對象的形式返回,每個對象包含有關識別文字的位置和內容的詳細信息。
然後,我們使用 compactMap 提取識別出的字符串。topCandidates 方法返回識別文字的最佳匹配。通過將候選數量的最大值設置為 1,我們確保只檢索到最佳候選。
最後,我們使用 joined 方法將所有識別出的字符串連接起來。
隨著 recognizeText 方法的就位,我們可以更新 onChange 修飾符來調用此方法,對所選照片進行文字識別。
.onChange(of: selectedItem) { oldItem, newItem in
Task {
guard let imageData = try? await newItem?.loadTransferable(type: Data.self) else {
return
}
await recognizeText(image: UIImage(data: imageData)!)
}
}
改動完成後,你現在可以在模擬器中運行應用程序來進行測試。如果你有包含文字的照片,此範例 App 應該能夠成功提取並顯示文字。
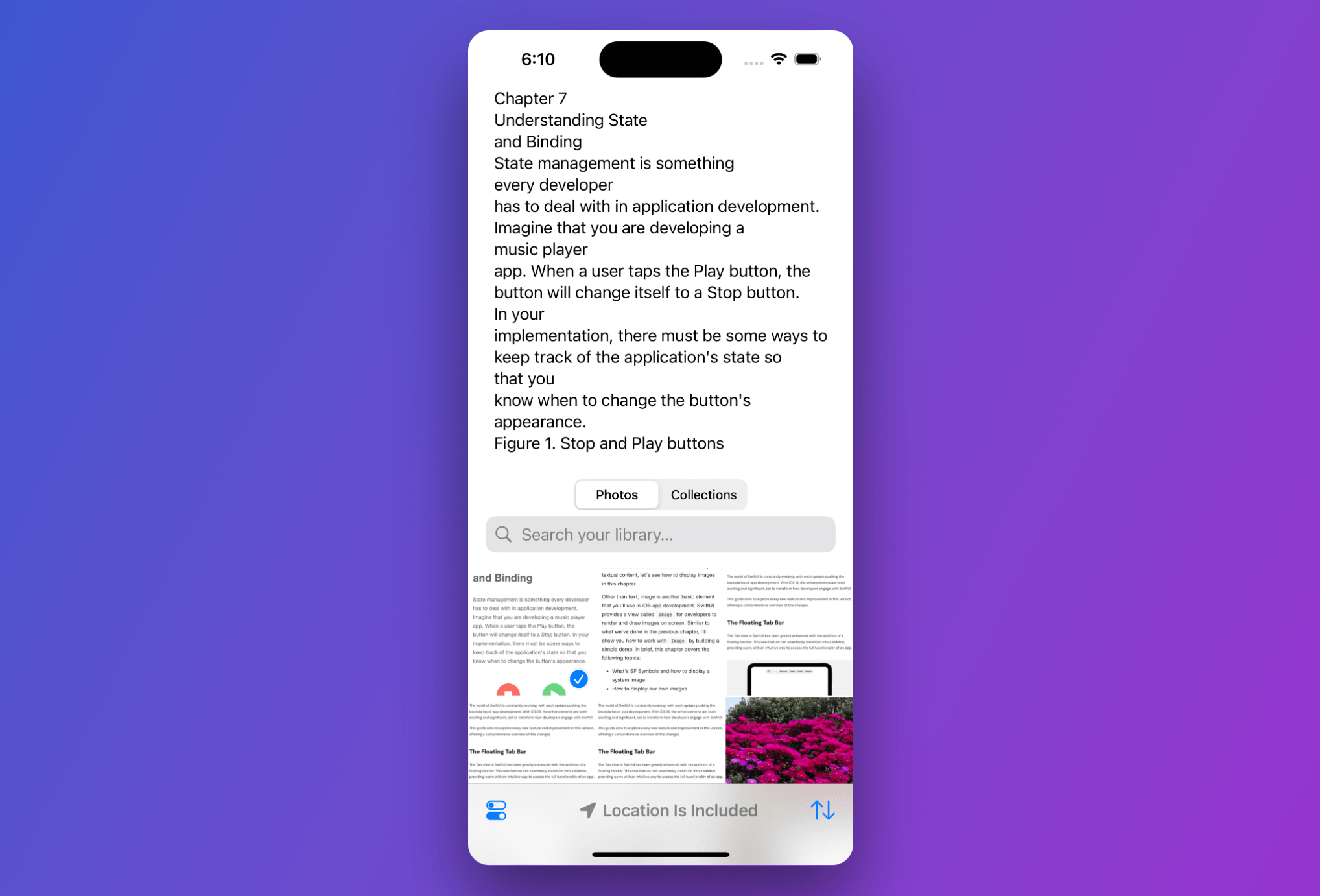
總結
隨著 iOS 18 引入新 Vision API ,我們現在可以非常輕鬆地開發文字識別功能,僅需幾行程式碼即可實現。簡化的APIs允許開發人員快速有效地將文字識別功能整合到應用程序中。
你對 Vision 框架的這個改進有什麼看法?歡迎在下方留言分享你的想法。


