

在今年的 WWDC 中,Apple 釋出了許多新框架(frameworks),Vision Framework 便是其中一個。藉由 Vision Framework ,你不需要高深的知識就可以很容易地在你的 App 中實作出電腦視覺技術(Vision Techniques)!Vision Framework 可以讓你的 App 執行許多強大的功能,例如識別人臉範圍及臉部特徵(微笑、皺眉、左眼眉毛等等)、條碼偵測、分類出圖像中的場景、物件偵測及追蹤以及視距偵測。
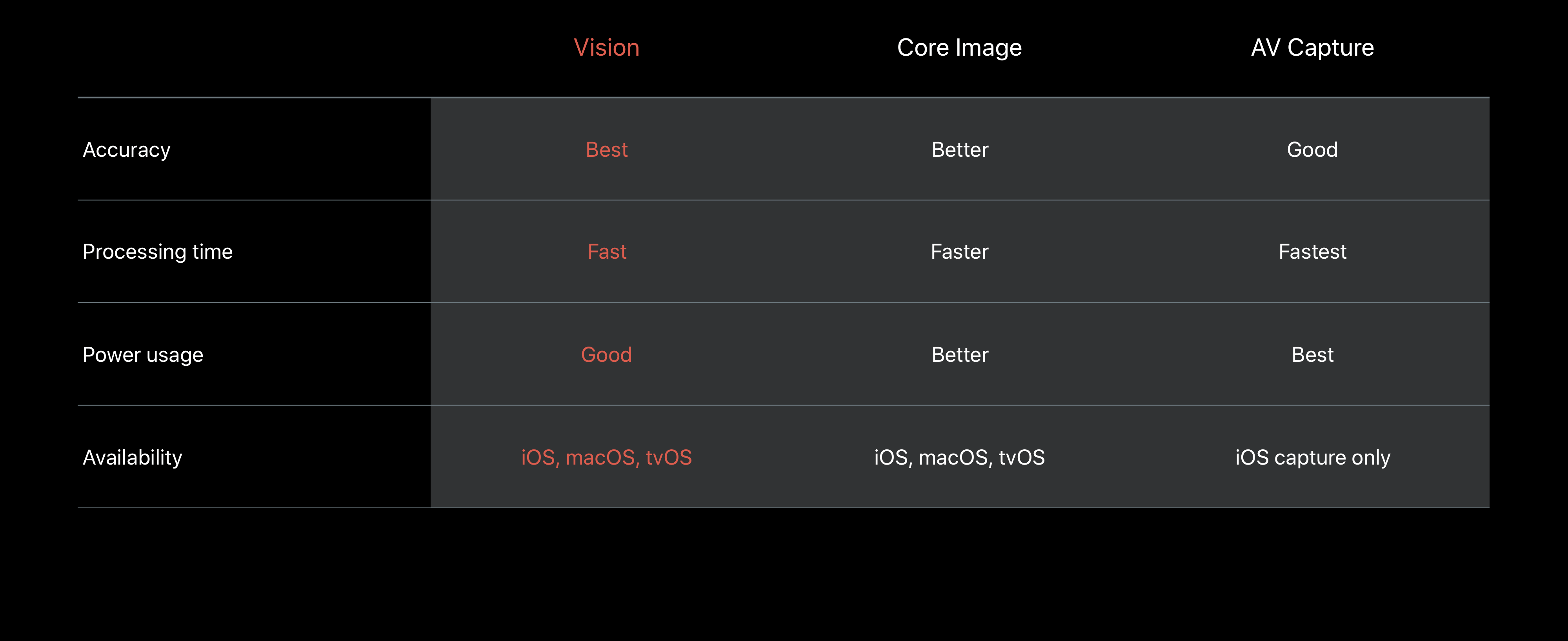
或許那些已經使用 Swift 開發程式一段時間的人會想知道既然已經有了Core Image 及 AVFoundation,為什麼還要推出 Vision 呢?如果我們看一下這張在 WWDC 演講中出現的表格,我們可以看到 Vision 的準確度(Accuracy)是最好的,同時也支援較多的平台。不過 Vision 需要較多的處理時間以及電源消耗。
在本次的教學中,我們將會利用 Vision Framework 來作出文字偵測的功能,並實作出一個能夠偵測出文字的 App ,不論字體、字型及顏色。如下圖所示,Vision Framework 可以識別出印刷及手寫兩種文字。

為了節省你建置 UI 所花的時間好專注在學習 Vision Framework 上,你可以下載 Starter Project 作為開始。
請注意你需要 Xcode 9 (beta 2 或以上版本)來完成本次教學,同時也需要一台 iOS 11 裝置來測試。所有的程式碼皆是以 Swift 4 撰寫。
建立即時影像
當你打開專案時,你可以看到視圖已經為你設定好放在 Storyboard 上了。接著進入 ViewController.swift ,你會發現由一些 outlet 及 function 所構成的程式骨架。我們的第一步就是要建立一個即時影像來偵測文字,在 imageView 底下宣告一個 AVCaptureSession 屬性:
var session = AVCaptureSession()
這樣就初始化了一個可以用來作即時(real-time)或非即時(offline)影音擷取的AVCaptureSession 物件。而這個物件在你要對即時影像進行操作時就會用上。接著,我們需要把這個 session 連接到我們的裝置上。首先把下面的函式放入 ViewController.swift 吧。
func startLiveVideo() {
//1
session.sessionPreset = AVCaptureSession.Preset.photo
let captureDevice = AVCaptureDevice.default(for: AVMediaType.video)
//2
let deviceInput = try! AVCaptureDeviceInput(device: captureDevice!)
let deviceOutput = AVCaptureVideoDataOutput()
deviceOutput.videoSettings = [kCVPixelBufferPixelFormatTypeKey as String: Int(kCVPixelFormatType_32BGRA)]
deviceOutput.setSampleBufferDelegate(self, queue: DispatchQueue.global(qos: DispatchQoS.QoSClass.default))
session.addInput(deviceInput)
session.addOutput(deviceOutput)
//3
let imageLayer = AVCaptureVideoPreviewLayer(session: session)
imageLayer.frame = imageView.bounds
imageView.layer.addSublayer(imageLayer)
session.startRunning()
}
如果你曾經用過 AVFoundation,你會發覺這個程式碼有點熟悉。如果你沒用過,別擔心。我們逐行的將程式碼說明一遍。
- 我們首先修改
AVCaptureSession的設定。然後我們設定AVMediaType為影片,因為我們希望是即時影像,此外它應該要一直持續地運作。 - 接著,我們要定義裝置的輸入及輸出。輸入是指相機所看到的,而輸出則是指應該顯示的影像。我們希望影像顯示為
kCVPixelFormatType_32BGRA格式。你可以從這裡了解更多關於像素格式的類型。最後,我們把輸入及輸出加進到AVCaptureSession。 - 最後,我們把含有影像預覽的 sublayer 加進到
imageView中,然後讓 session 開始運作。
呼叫在 viewWillAppear 方法裡的這個函式:
override func viewWillAppear(_ animated: Bool) {
startLiveVideo()
}
因為在 viewWillAppear() 中還沒決定 imageView 的範圍,所以覆寫 viewDidLayoutSubviews() 方法來更新圖層的範圍。
override func viewDidLayoutSubviews() {
imageView.layer.sublayers?[0].frame = imageView.bounds
}
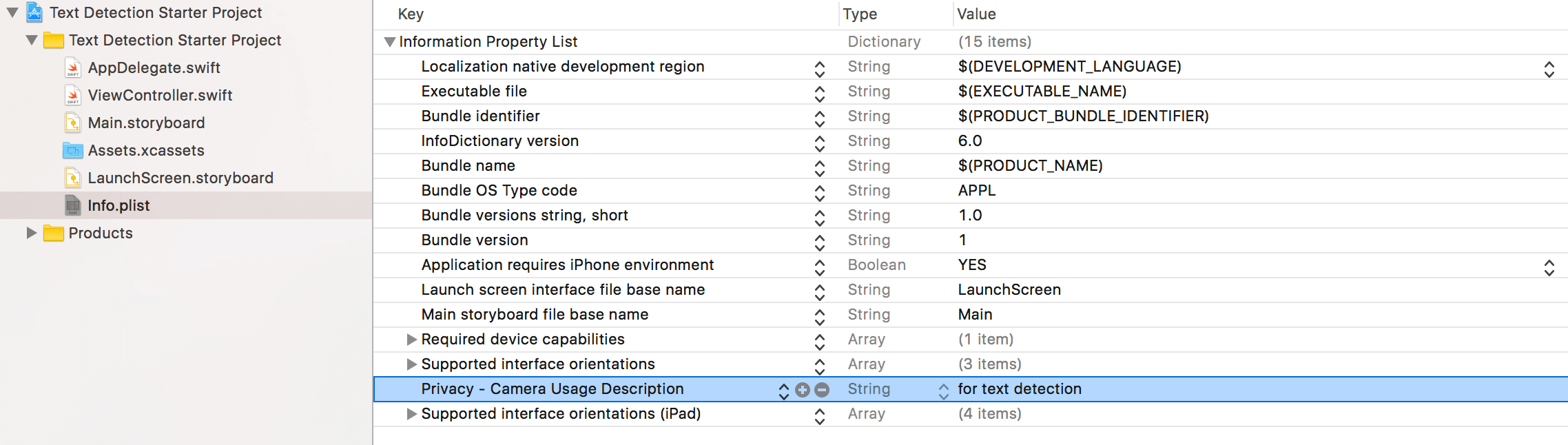
在執行之前,要在 Info.plist 加入一個條目來說明為何你需要使用到相機功能。這自 Apple 發佈 iOS 10 後,都是必須添加的步驟。
現在即時影像應該會如預期般的運作。然而,因為我們還沒實作 Vision Framework,所以還沒有文字偵測功能。而這就是我們接下來要完成的部份。
實作文字偵測
在我們實作文字偵測(Text Detection)之前,我們需要了解 Vision Framework 是如何運作的。基本上,在你的 App 裡實作 Vision 會有三個步驟,分別是:
- Requests – Requests 是指當你要求 Framework 為你偵測一些東西時。
- Handlers – Handlers 是指當你想要 Framework 在 Request 產生後執行一些東西或處理這個 Request 時.
- Observations – Observations 是指你想要用你提供的資料做什麼。

現在,讓我們從 Request 開始吧。在初始化的變數 session 底下宣告另一個變數:
var requests = [VNRequest]()
我們建立了一個含有一個通用類別 VNRequest 的陣列。接著,讓我們在 ViewController 類別裡建立一個函式來進行文字偵測吧。
func startTextDetection() {
let textRequest = VNDetectTextRectanglesRequest(completionHandler: self.detectTextHandler)
textRequest.reportCharacterBoxes = true
self.requests = [textRequest]
}
在這個函式裡,我們建立一個 VNDetectTextRectanglesRequest 的常數 textRequest。基本上它是 VNRequest 的一個特定型態,只能尋找文字中的矩形。當 Framework 完成了這個 Request,我們希望它呼叫 detectTextHandler 函式。同時我們也想要知道 Framework 辨識出了什麼,這也是為什麼我們設定 reportCharacterBoxes 屬性為 true。最後,我們設定早先建立好的變數requests 為 textRequest。
現在,你應該會得到一些錯誤訊息。這是因為我們還沒定義應該用來處理 Request 的函式。為了解決這些錯誤,建立一個函式像:
func detectTextHandler(request: VNRequest, error: Error?) {
guard let observations = request.results else {
print("no result")
return
}
let result = observations.map({$0 as? VNTextObservation})
}
在上面的程式碼,我們首先定義一個含有所有 VNDetectTextRectanglesRequest 結果的常數 observations。接著,我們定義另一個常數 result,它將遍歷所有 Request 的結果然後轉換為 VNTextObservation 型態。
現在,更新 viewWillAppear() 方法:
override func viewWillAppear(_ animated: Bool) {
startLiveVideo()
startTextDetection()
}
如果你現在執行你的 App,你不會看到任何的不同。這是因為雖然我們告訴 VNDetectTextRectanglesRequest 要回報字母方框,但是沒有告訴它該如何回報。這將是我們接下來要完成的部份。
繪製方框
在我們的 App 中,我們會讓 Framework 繪製兩個方框:一個所偵測的每個字母,另一個則是整個單字。讓我們就從製作繪製每個單字的方框開始吧!
func highlightWord(box: VNTextObservation) {
guard let boxes = box.characterBoxes else {
return
}
var maxX: CGFloat = 9999.0
var minX: CGFloat = 0.0
var maxY: CGFloat = 9999.0
var minY: CGFloat = 0.0
for char in boxes {
if char.bottomLeft.x < maxX {
maxX = char.bottomLeft.x
}
if char.bottomRight.x > minX {
minX = char.bottomRight.x
}
if char.bottomRight.y < maxY {
maxY = char.bottomRight.y
}
if char.topRight.y > minY {
minY = char.topRight.y
}
}
let xCord = maxX * imageView.frame.size.width
let yCord = (1 - minY) * imageView.frame.size.height
let width = (minX - maxX) * imageView.frame.size.width
let height = (minY - maxY) * imageView.frame.size.height
let outline = CALayer()
outline.frame = CGRect(x: xCord, y: yCord, width: width, height: height)
outline.borderWidth = 2.0
outline.borderColor = UIColor.red.cgColor
imageView.layer.addSublayer(outline)
}
我們一開始先在函式裡定義一個常數 boxes,他是由 Request 所找到的所有 characterBoxes 的組合。然後,我們定義一些在視圖上的座標點來幫助我們定位方框。最後,我們建立一個有給定範圍約束的 CALayer 並將它應用在我們的 imageView 上。接下來,就讓我們來為每個字母建立方框吧。
func highlightLetters(box: VNRectangleObservation) {
let xCord = box.topLeft.x * imageView.frame.size.width
let yCord = (1 - box.topLeft.y) * imageView.frame.size.height
let width = (box.topRight.x - box.bottomLeft.x) * imageView.frame.size.width
let height = (box.topLeft.y - box.bottomLeft.y) * imageView.frame.size.height
let outline = CALayer()
outline.frame = CGRect(x: xCord, y: yCord, width: width, height: height)
outline.borderWidth = 1.0
outline.borderColor = UIColor.blue.cgColor
imageView.layer.addSublayer(outline)
}
跟我們前面所撰寫的程式碼相似,我們使用 VNRectangleObservation 來定義約束條件,讓我們更容易地勾勒出方框。現在,我們已經設置好所有的函式了。最後一步便是要連接所有的東西。
串接程式
有兩個主要的部分需要連接。第一個是處理 Request 的函式。我們先來完成個這個吧。像這樣更新 detectTextHandler 方法:
func detectTextHandler(request: VNRequest, error: Error?) {
guard let observations = request.results else {
print("no result")
return
}
let result = observations.map({$0 as? VNTextObservation})
DispatchQueue.main.async() {
self.imageView.layer.sublayers?.removeSubrange(1...)
for region in result {
guard let rg = region else {
continue
}
self.highlightWord(box: rg)
if let boxes = region?.characterBoxes {
for characterBox in boxes {
self.highlightLetters(box: characterBox)
}
}
}
}
}
我們從讓程式碼非同步執行開始。首先,我們移除 imageView 最底層的圖層(如果你有注意到,我們先前添加了許多圖層到 imageView 中。)接下來,我們從 VNTextObservation 的結果裡確認是否有區域範圍存在。現在,我們呼叫沿著範圍(或者說單字)繪製方框的函式。然後我們確認是否有字符方框在這個範圍裡。如果有,我們呼叫方法來沿著字母繪上方框。
現在,連接所有東西的最後一個步驟就是以即時影像來執行我們的 Vision Framework 程式碼。我們需要做的是攝製影像並將其轉換為 CMSampleBuffer。在 ViewController.swift 的擴展(Extension)中插入下面的程式碼:
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else {
return
}
var requestOptions:[VNImageOption : Any] = [:]
if let camData = CMGetAttachment(sampleBuffer, kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, nil) {
requestOptions = [.cameraIntrinsics:camData]
}
let imageRequestHandler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, orientation: 6, options: requestOptions)
do {
try imageRequestHandler.perform(self.requests)
} catch {
print(error)
}
}
在那邊打住一下。這是我們程式碼的最後部分了。這個擴展調用了 AVCaptureVideoDataOutputSampleBufferDelegate 協定。基本上這個函式所做的就是它確認 CMSampleBuffer 是否存在以及提供一個 AVCaptureOutput。接著,我們建立一個 VNImageOption 型態的字典(Dictionary)變數 requestOptions。VNImageOption 是一個結構(struct)類型,它可以從相機中保持著資料及屬性。最後我們建立一個 VNImageRequestHandler 物件並執行我們早先建立的文字 Request。
Build 及 Run 你的 App,看看你得到什麼!

小結
Well,接下來是個大工程呢!試著用不同字型、大小、字體、粗細等等來測試 App 吧。看看是否你可以擴展這個 App 。你可以在下面的回應中貼上你如何擴展這個專案。你也可以結合 Vision Framework 及 Core ML。想要更多關於 Core ML 的資訊,可以參閱我先前撰寫的 Core ML 介紹教學。
你可以參考放在 GitHub 上的 完整專案。
更多關於 Vision Framework 的細節可以參考 Vision Framework 官方文件。你也可以參考 WWDC 關於 Vision Framework 的演講:
Vision Framework: Building on Core ML
Advances in Core Image: Filters, Metal, Vision, and More