

樣式轉換 (Style Transfer) 是一個非常熱門的深度學習課題,它可以讓我們在一個圖像上套用另一個圖像的視覺樣式,來改變圖像的構圖。
透過神經樣式轉換模型 (Neural Style Transfer Model),我們可以建構很多令人驚艷的東西,像是建構藝術照片編輯器、或是應用最新設計的樣式為遊戲設計賦予新樣貌等。它非常方便,也可以使用資料擴充。
在 WWDC 2020,Create ML(Apple 的模型建構框架)加入了樣式轉換模型 (Style Transfer Model),功能大大提升。儘管 Xcode 12 隨附這項更新,但你還需要 macOS Big Sur(在撰寫本篇文章時還是 Beta 版本)來訓練樣式轉換模型。
初探 Create ML 的樣式轉換
現在,Create ML 讓我們可以使用 Macbook 直接訓練樣式轉換模型。你可以訓練圖像與影像的樣式轉換卷積神經網路 (Style Transfer Convolutional Neural Networks),影像的轉換只會使用有限的卷積過濾器,讓它最佳化實時的圖像處理。
在開始之前,你需要三項東西:
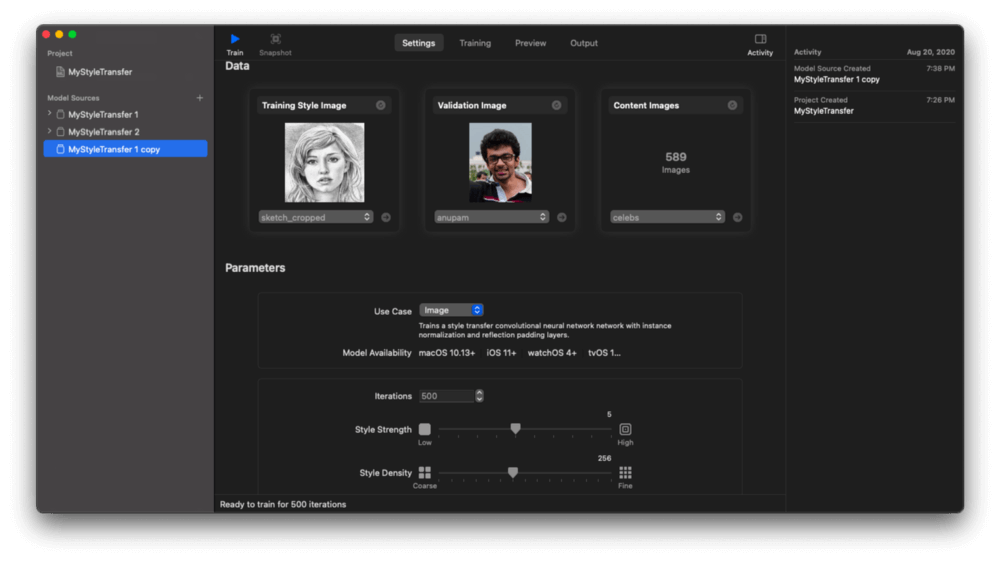
- 一個樣式圖像(也可以叫做樣式參考圖像)。通常來說,你可用著名畫作或是抽象藝術圖像,來讓你的模型學習風格。在範例中,我們會在第一個模型裡使用鉛筆素描圖像(參看下面的螢幕截圖)。
- 一張驗證圖像,它為我們在訓練過程中可視化模型品質。
- 內容圖像的資料集,這是我們的訓練資料。為了取得最佳結果,這裡使用的圖像目錄,最好與你執行推算時使用的圖像相似。
在本篇文章中,我將使用這個名人圖集作為內容圖像。
在訓練模型之前,讓我們先來看看 Create ML 樣式轉換設定頁籤。
以下的驗證圖像顯示每個迭代 (iteration) 區間內,即時套用的樣式轉換:
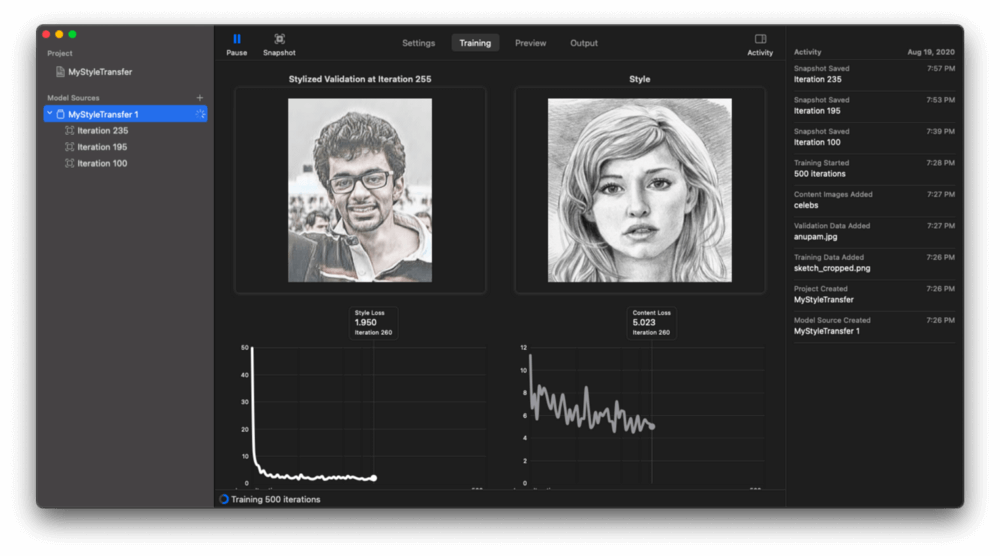
讓我們來看看樣式損失 (Style Loss) 與內容損失(Content Loss) 的折線圖,這是了解樣式和內容圖像之間平衡的指標。通常來說,樣式損失應該隨時間減少,這表示神經網路正在學習調用樣式圖像的藝術特徵。
雖然預設模型參數運作得不錯,不過 Create ML 允許我們因應特定條件來作客製化。
低樣式強度參數僅使用樣式圖像微調部分背景,保持圖像主體完整。如果把樣式強度參數設定為高,就會在圖像邊緣上給予更多樣式紋理。
同樣地,粗糙的樣式密度會使用樣式圖像的高階細節(訓練這類的模型速度要快得多),而細密的密度則讓模型學習細微的細節。
Create ML 樣式轉換模型訓練預設迭代為 500 次,這對於大部分使用案例來說都是理想的數值。迭代是完成一個階段所需的批次數量,一個階段等於整個資料集的一個訓練週期。例如,如果訓練的資料集是由 500 張圖像組成,而批次的數量是 50,那就表示 10 次迭代完成一個階段(注意:Create ML 模型訓練並不會告訴你批次大小。)
今年,Create ML 還引入了另外一個新功能:模型快照 (Model Snapshots)。這項功能讓我們可以在模型訓練期間擷取 Core ML 模型,並匯出到 App 裡。然而,來自快照的模型並未最佳化檔案大小,而且明顯地大於完成訓練後的模型。具體來說,我擷取的 Core ML 模型快照大小為 5 – 6 MB,而最終模型大小為 596 KB。
我比較了不同迭代中的模型快照,結果如下:
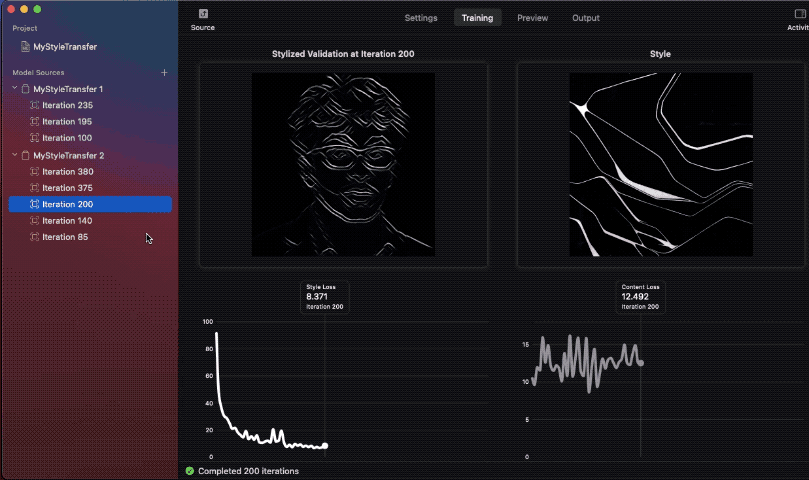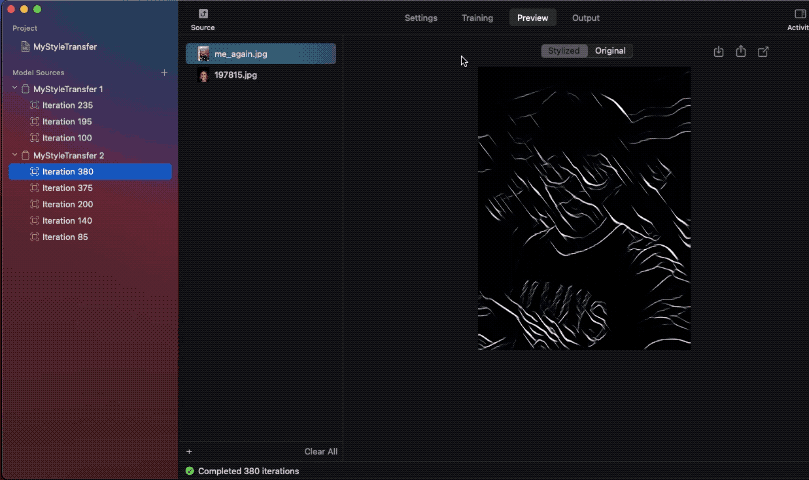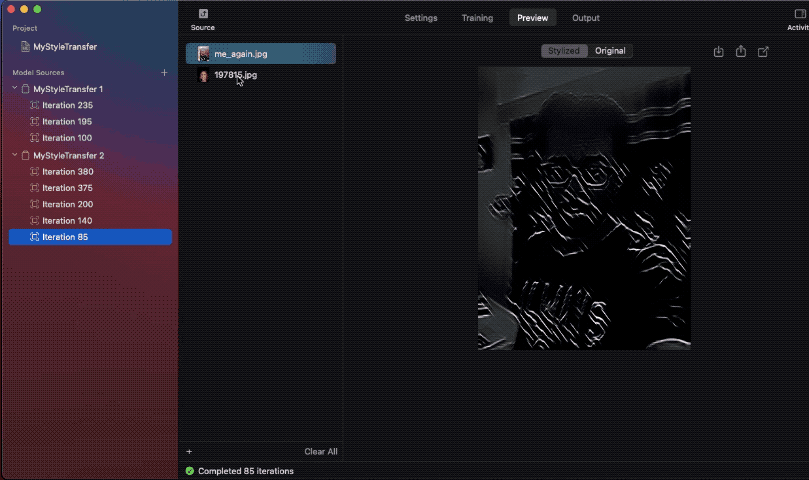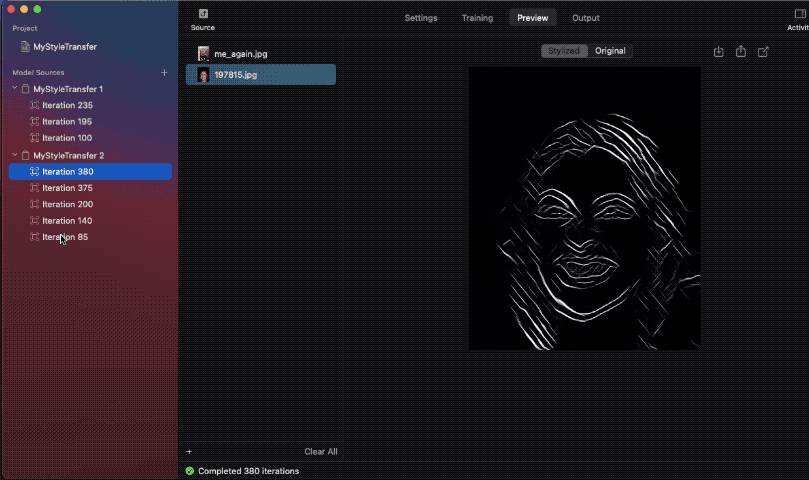
請注意,在其中一張圖像中,樣式無法構成完整的圖像。這是因為使用的樣式圖像尺寸較小,所以網路無法學習足夠的樣式資訊,導致合成圖像的品質不佳。
理想來說,樣式圖像應為 512 px 以上,這樣才能確保較好的結果。
目標
在接下來的部分,我們將建構一個 iOS App 來實時運行樣式轉換模型。讓我們先看看實作步驟的概覽:
- 從三個影像樣式轉換神經網路模型來分析結果。其中一個是用預設參數來訓練的,其他則用高與低的樣式強度參數訓練。
- 在 iOS App 裡使用 AVFoundation 來實作客製化相機。
- 在實時相機上執行建構好的 Core ML 模型。我們會使用 Vision 請求來快速在螢幕上執行、推算、及繪製樣式相機影格。
- 檢視 CPU、GPU 與神經引擎 (Neural Engine) 的結果。
要找一幅具有良好藝術效果的樣式圖像非常棘手。幸運的是,我簡單地在 Google 搜尋找到這張圖像。
分析不同強度的樣式轉換模型
我已經用同一組資料集訓練好了三個模型。來看看結果:
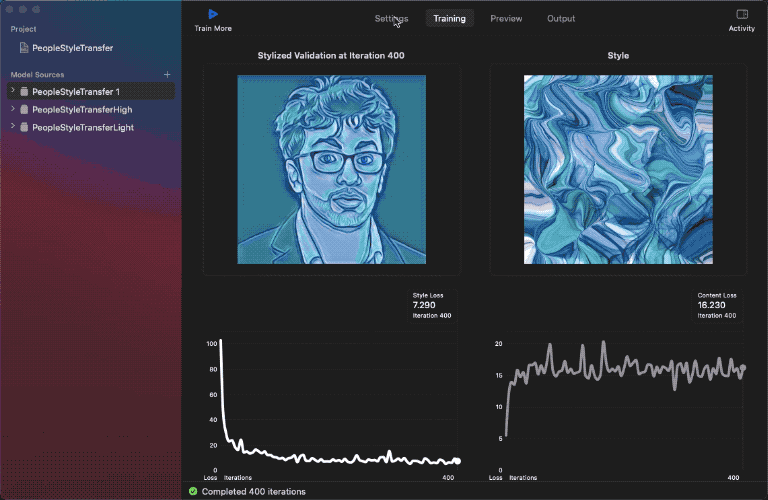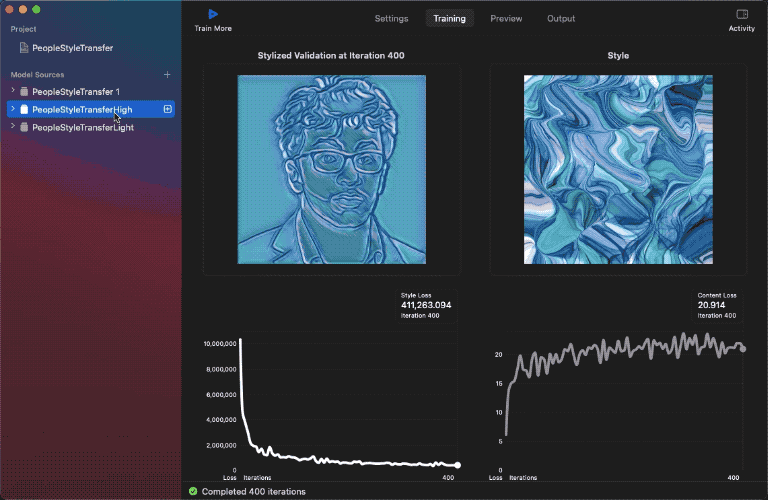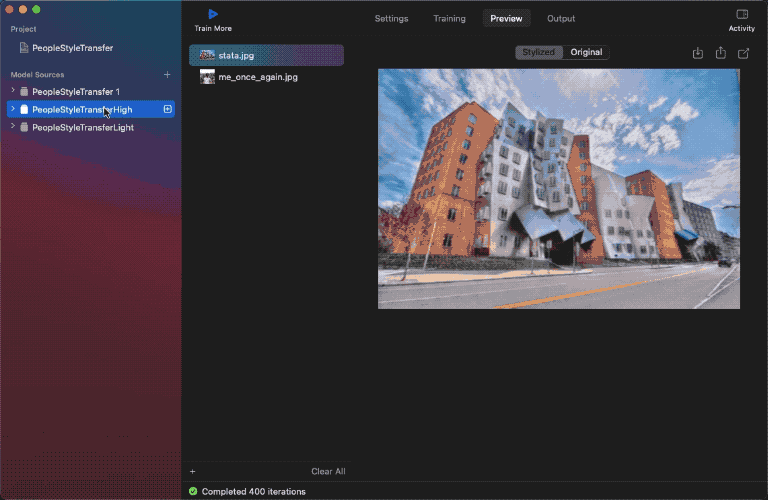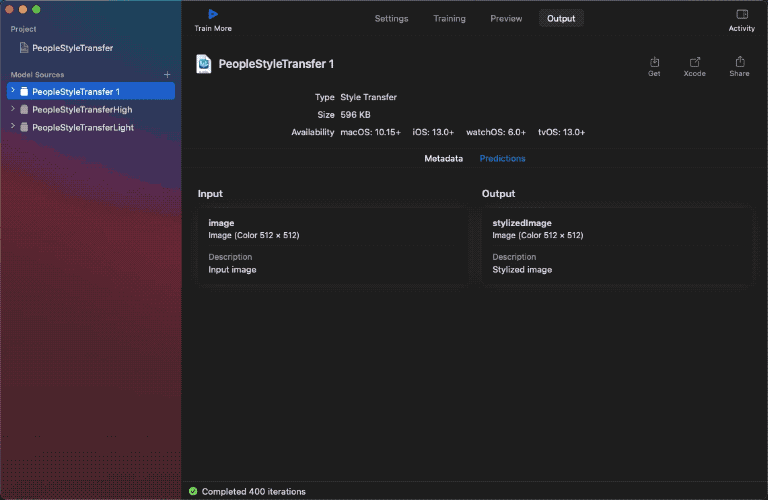
如你所見,使用低強度模型,樣式圖像幾乎沒有對內容圖像造成影響;但使用高強度模型,內容圖像的邊緣就有更多樣式效果。
現在,我們已經準備好將模型(大約 0.5 MB 的大小)轉移到 App 中。
Create ML 會讓我們預覽影像結果,不過速度非常地慢。幸運的是,我們很快就會在範例 App 裡實時顯示它們。
AVFoundation 基礎
AVFoundation 是 Apple 一個可高度客製化的多媒體內容框架。你可以繪畫客製的遮罩、微調相機設定、使用深度輸出進行照片切割、以及分析影格。
我們主要專注於分析影格、對影格進行樣式轉換、並在 UIImageView 上顯示它們,來建構一個實時相機功能。(你也可以使用 Metal 進行最佳化,但為簡單起見,本次教學中將跳過這個部分。)
基本來說,要建構一個客製化相機,我們需要使用以下元件:
AVCaptureSession:這個元件用來管理整個相機的 Session。它的功能包括了存取 iOS 裝置輸入、及傳送資料到輸出裝置。AVCaptureSession 也讓我們為不同的 Capture Session 定義Preset類型。AVCaptureDevice:這個元件讓我們選擇前置或後置鏡頭。我們可以選擇預設設定,或是使用AVCaptureDevice.DiscoverySession來過濾及選擇特定的硬體功能,像是原深感測 (TrueDepth) 或廣角 (WideAngle) 相機。AVCaptureDeviceInput:這個元件提供從 Capture Device 擷取的多媒體來源,並將其送往 Capture Session。AVCaptureOutput:這是一個抽象類別,提供輸出內容到 Capture Session。它也讓我們處理相機方向。我們可以設定多個輸出(像是相機與麥克風)。比如說,如果你要拍攝相片及電影,那麼就要添加AVCaptureMovieFileOutput及AVCapturePhotoOutput。在我們的範例中,我們將使用AVCaptureVideoDataOutput,來提供影像影格供我們處理。AVCaptureVideoDataOutputSampleBufferDelegate:這是一個協定,讓我們可以在didOutput協定方法裡存取每個影格緩衝 (Frame Buffer)。要啟動接受影格,我們需要調用AVCaptureVideoDataOutput裡的setSampleBufferDelegate。AVCaptureVideoPreviewLayer:這基本上是一個CALayer,它視覺地顯示來自 Capture Session 輸出的實際相機畫面。我們可以使用遮罩及動畫來轉變圖層。對於 Sample Buffer 委託方法的運作來就,這個設定十分重要。
設定我們的客製化相機
首先,把 NSCameraUsageDescription 相機權限添加到 Xcode 專案的 info.plist。
現在,是時候在 ViewController.swift 建立一個 AVCaptureSession:
let captureSession = AVCaptureSession()
captureSession.sessionPreset = AVCaptureSession.Preset.medium接著,在 AVCaptureDevice 實例裡可使用的相機類型列表中,讓我們過濾並選擇廣角相機。然後,將它添加至 AVCaptureInput,並將其設定在 AVCaptureSession 上:
let availableDevices = AVCaptureDevice.DiscoverySession(deviceTypes: [.builtInWideAngleCamera], mediaType: AVMediaType.video, position: .back).devices
do {
if let captureDevice = availableDevices.first {
captureSession.addInput(try AVCaptureDeviceInput(device: captureDevice))
}
} catch {
print(error.localizedDescription)
}現在,輸入已經設定好了,讓我們添加影像輸出到 captureSession 上:
let videoOutput = AVCaptureVideoDataOutput()
videoOutput.alwaysDiscardsLateVideoFrames = true
videoOutput.setSampleBufferDelegate(self, queue: DispatchQueue(label: "videoQueue"))
if captureSession.canAddOutput(videoOutput){
captureSession.addOutput(videoOutput)
}alwaysDiscardsLateVideoFrames 屬性可以確保延遲的影格會被丟棄,以減少延遲的情況。
最後,加入以下程式碼來避免相機轉向:
guard let connection = videoOutput.connection(with: .video)
else { return }
guard connection.isVideoOrientationSupported else { return }
connection.videoOrientation = .portrait備註:為了確保所有的轉向,你需要基於裝置現在的方向設定 videoOrientation。在本教學的最後會有程式碼範例。
現在,我們終於可以添加預覽圖層,並啟動 Camera Session:
let previewLayer = AVCaptureVideoPreviewLayer(session: captureSession)
view.layer.addSublayer(previewLayer)
captureSession.startRunning()以下是我們剛建立的 configureSession() 方法:

運用 Vision 為 Core ML 模型實時執行樣式轉換
現在來到了機器學習的部分。我們會使用 Vision 框架,為樣式轉換模型的輸入圖像做前處理。
讓 ViewController 符合 AVCaptureVideoDataOutputSampleBufferDelegate 協定後,我們可以使用以下的方法取得每個影格:
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate{
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {}
}從上面的 Sample Buffer 實例,我們可以取得 CVPixelBuffer 實例,並且將它傳送到 Vision 請求:
guard let model = try? VNCoreMLModel(for: StyleBlue.init(configuration: config).model) else { return }
let request = VNCoreMLRequest(model: model) { (finishedRequest, error) in
guard let results = finishedRequest.results as? [VNPixelBufferObservation] else { return }
guard let observation = results.first else { return }
DispatchQueue.main.async(execute: {
self.imageView.image = UIImage(pixelBuffer: observation.pixelBuffer)
})
}
guard let pixelBuffer: CVPixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return }
try? VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:]).perform([request])以 VNCoreMLModel 作為容器,我們以下列方式在當中實例化 Core ML 模型:
StyleBlue.init(configuration: config).modelconfig 是 MLModelConfiguration 型別的實例,用來定義 computeUnits 屬性。這個屬性可讓我們設定 cpuOnly、cpuAndGpu 或是 all(Neural Engine),以在我們想要的裝置硬體上執行。
let config = MLModelConfiguration()
switch currentModelConfig {
case 1:
config.computeUnits = .cpuOnly
case 2:
config.computeUnits = .cpuAndGPU
default:
config.computeUnits = .all
}備註:我們已設定了一個 UISegmentedControl UI 控件,讓我們可以切換上面的模型配置。
我們在 VNCoreMLRequest 中傳遞 VNCoreMLModel,VNCoreMLRequest 會回傳 VNPixelBufferObservation 型別的觀察 (Observations)。
VNPixelBufferObservation 是 VNObservation 的子類別,它會回傳 CVPixelBuffer 的影像輸出。
我們利用下面的 Extension 來轉換 CVPixelBuffer 為 UIImage,並將它繪製在螢幕上。
extension UIImage {
public convenience init?(pixelBuffer: CVPixelBuffer) {
var cgImage: CGImage?
VTCreateCGImageFromCVPixelBuffer(pixelBuffer, options: nil, imageOut: &cgImage)
if let cgImage = cgImage {
self.init(cgImage: cgImage)
} else {
return nil
}
}
}呼~!我們已經建立好實時樣式轉換 iOS App 了。
以下是在 iPhone SE 上執行 App 的成果:
從上面的 gif 中可見,頂部的分類選擇器讓你在兩個模型之間挑選。StarryBlue 是以預設樣式強度訓練,而 Strong 頁籤則是執行第二個高樣式強度的模型。
讓我們看看,在 Neural Engine 上運行時,樣式轉換預測是如何實時進行的。
備註:因為 gif 檔案大小以及畫質限制,我錄製了一段影片,來示範 CPU、GPU、以及 Neural Engin 上的實時樣式轉換。影片會比上面的 gif 更加順暢。
你可以在 這個 GitHub Repository 中,參考這個 Core ML 樣式轉換模型 App 的完整程式碼。
iOS 14 的 Core ML 引入了模型加密 (Model Encryption),因此理論上可以我加密這個模型。但是本著學習精神,我會免費提供上述創建的模型。
總結
機器學習的未來顯然是不需要程式碼的, MakeML、Fritz AI、以及 Apple 的 Create ML 等平台將引領趨勢,並提供易於使用的工具及平台,以快速訓練可在手機上使用的機器學習模型。
Create ML 今年還引入支援人類活動分類的模型訓練,但我相信樣式轉換會是快速地被 iOS 開發者所用應用的功能。如果你希望建構一個包含多個樣式圖像的單一模型,可以使用 Turi Create。
現在,你可以使用神經樣式轉換神經網路,以零成本(除非你要把 App 上傳到 App Store)建構基於 AI、類似 Prisma 的 App。
樣式轉換也適用於 ARKit 物件,給予它們一個完全不同的外觀。我們將在下篇教學討論這個部分,請密切留意我們的更新。
本篇文章到此為止,感謝你的閱讀。